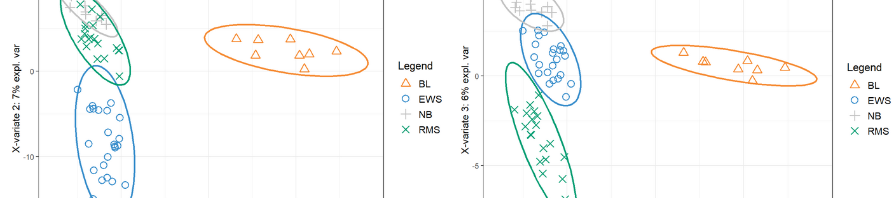
This course is designed for:
- Beginners looking for an introduction to mixOmics methods for single – and multi-omics analyses.
- Current mixOmics users who want to deepen their understanding of the mixOmics methods.
- Users who would like more guidance on analyzing their own data (we also provide exemplar datasets).
The workshop is self-paced and spans across 7 weeks. There are 4 Q&A live sessions, and many opportunities to interact with the cohort and your instructor Prof Kim-Anh Lê Cao via Slack. BYO data is encouraged: we provide advice so that you can analyse your own data with mixOmics tools as part of your learning process. A good working knowledge in R programming (e.g. handling data frame, perform simple calculations and display simple graphical outputs) is essential to fully benefit from the course*.
According to our past participants, a time commitment of 5-8h/week was sufficient to feel that they were progressing. Here is some feedback from a previous course.
We provide a certificate of attendance or completion.
Register here, places are limited!
(make sure you put the right discount code, see tiered fees below)
Fees
Research Higher Degree students enrolled at a University: $550 AUD (incl. GST) [discount code: MIXO_RHD]
Staff and members from Universities & Not-for-profit organisations: $900 (incl. GST) [discount code: MIXO_NFP_STAFF]
Other industries: $1,450 AUD (incl. GST)
Discounts of 5% for a group of 3-9 learners and 10% for 10+ learners, however, this will require a single invoice per group.
These funds go towards the support of a software developer to maintain the package. If you need an invoice, contact Student Support at continuing-education[at]unimelb.edu.au
Teaching Period Dates
Teaching commences: Monday, 23 Feb 2026, 9:00 am AEST (note Australian time!)
Q&A live webinars are scheduled on Thursdays 6pm AEST / 8am CET during the first 4 weeks (26th Feb, 5th, 12th and 19th March).
An additional session might be added on Fridays 9am AEST ( = Thursdays 2pm PST / 5pm EST / 9pm CET)
- Teaching concludes: Friday, 20 March 2025, 11:59 pm AEST (after 4 weeks)
- (non marked) Assessment due: Friday 5 April 2025 (2 weeks prep)
- Peer-review of assessment due: Friday 11 April 2025 (1 week prep)
The course is divided into theory (50%) and hands-on practice, with the opportunity to analyse your own data. The exercises and assignments are in R. Participants are encouraged to use RStudio and Rmarkdown (template and R code provided).
*Need an R refresher?
Learners who are not proficient in R do not get the full benenefit of the course (based on their own, honest, feedback!) For those looking for an R refresher well ahead of the course:
https://monashdatafluency.github.io/r-intro-2/index.html
The R cheatsheets for reference: https://iqss.github.io/dss-workshops/R/Rintro/base-r-cheat-sheet.pdf